
As natural language processing tasks continue to become more complex, large language models (LLMs) have become increasingly popular. However, fitting these models on hardware can be a daunting task. LLMs can have millions or even billions of parameters, requiring large amounts of memory and computation power to train effectively.
During my work at Schibsted, I had the opportunity to work on this exciting topic. In this blog post, we will explore
different techniques to fit LLMs on hardware and optimise memory usage.
how these techniques can be used in Microsoft DeepSpeed, one of the leading frameworks to train large models (I don’t have much experience in DeepSpeed myself, but I found it quite interesting to see, what knobs you can modify. The documentation is also a good place to read up in more detail)
We also created a GPT model memory calculator that allows you to predict the memory usage for different techniques.
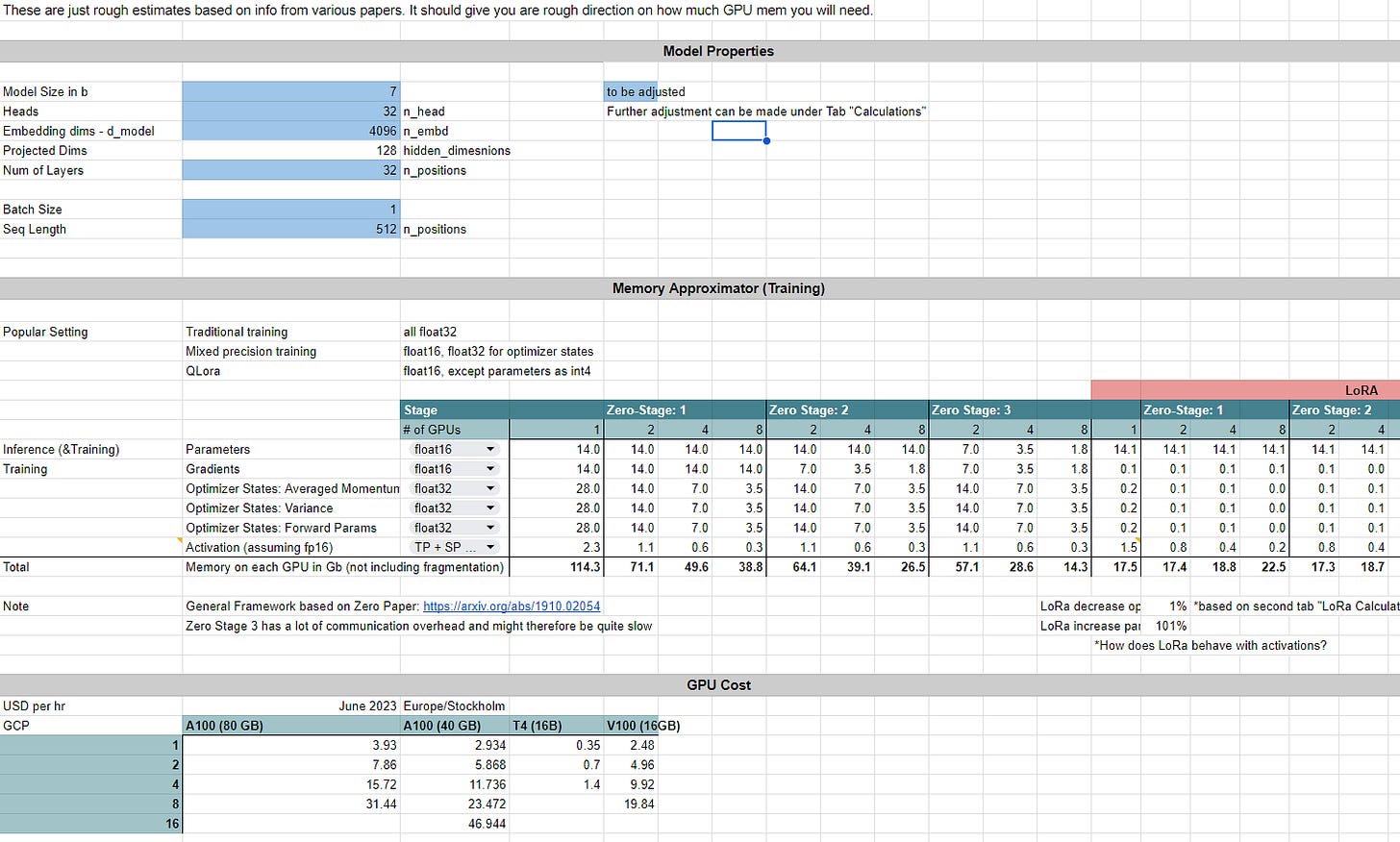
Screenshot: This is the memory calculator, feel free to make a copy
Additionally, I started building a few scripts to measure the actual memory consumption of some models. It is in really early stage, but feel free to be inspired or even contribute: https://github.com/dpleus/transparentmodel
Being able to estimate and reduce memory usage has the following advantages:
You can train models in a more systematic way instead of brute-forcing through OOM (out of memory) errors
Better informed trade-offs to reduce memory usage and often sacrifice model accuracy or computational efficiency (I am planning an article on that)
Make more cost sensitive discussions. Do I really need the big machinery or can I train cheaper by using some advanced techniques.
How much memory does a LLM need?
Parameter, Activations and Optimizer States
The majority of memory utilised by machine learning models consists of numerical values. Usually, these values can be classified as:
Parameters, who hold the weights that the model is trained on.
Activations, the results of the input and parameters
Once the model has run a forward pass and the parameters need to be updated:
Gradients, the direction/magnitude in which the weights have to change
Optimizer States: Most updates are not solely done on the gradients, but also based on historical updates.
All of those elements are saved as floating numbers, and for years, the standard has been using 32-bit floating numbers to provide higher precision and the ability to incorporate more information.

Source: https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407
However, recent advancements in research have shown that it's possible to achieve similar results using lower precision data types.
Mixed-Precision Training
Paper: Mixed Precision Training, Micikevicius et al (2017)
One technique to optimise memory usage when fitting LLMs on hardware is mixed-precision training. Mixed-precision training involves using a combination of 16-bit and 32-bit floating-point precision during training. 16-bit precision requires less memory than 32-bit precision, allowing for larger batch sizes and faster training times.
Effect on Memory:
In the figure below you can see the elements required for mixed-precision training. Parameters and gradients are kept in 16-bit, while the optimizer states (in case Adam) are in 32-bit. Additionally we keep a 32-bit copy of the parameters.

Source: Own graphic, based on ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, Rajbhandari et al. (2019)
The cited paper describes the impact as following:
Even though maintaining an additional copy of weights increases the memory requirements for the weights by 50% compared with single precision training, impact on overall memory usage is much smaller. For training memory consumption is dominated by activations, due to larger batch sizes and activations of each layer being saved for reuse in the back-propagation pass. Since activations are also stored in half-precision format, the overall memory consumption for training deep neural networks is roughly halved.
Usage in DeepSpeed

In mixed precision training, dynamic loss scaling is a technique used to prevent underflow or overflow errors when using low-precision data types, such as float16, to represent the gradients during backpropagation. The basic idea is to scale the loss function by a factor that is adjusted dynamically during training to maintain a certain range of values.
How to decrease memory usage?
Zero Redundancy Optimizer (ZeRO)
Paper: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, Rajbhandari et al. (2019) ZeRO-Offload: Democratizing Billion-Scale Model Training, Ren et al. (2021)
Zero Redundancy Optimizer (ZeRO) is a technique designed to work with distributed training, which is necessary when the model is too large to fit in the memory of a single GPU or a single machine. ZeRO partitions the model's parameters (and gradients and optimizer states) across multiple GPUs. So every GPU runs a full model, but does not store all the parameters. Additionally, ZeRO uses a form of data parallelism - it is split, distributed to the device and fed into the model.
ZeRO has three modes of operation: ZeRO-1, ZeRO-2, and ZeRO-3. These modes determine how the model's parameters, gradients, and optimizer states are distributed across devices.
ZeRO-1: In ZeRO-1, only the optimizer states are partitioned and distributed across devices. Parameters and gradients are kept on each device separately. Each device does the forward pass and calculates the gradients. Then every device updates the parameter it helds the optimizer states for. At the end, the updated weights are distributed across all the devices.
ZeRO-2: In ZeRO-2, both the model's optimizer states and gradients are partitioned and distributed across devices. It works like ZeRO-1 except that the gradients are also distributed.
ZeRO-3: In ZeRO-3, all components of the training process are distributed across devices: the model's parameters, gradients, and optimizer states. This blog entry from Microsoft shows how ZeRo-3 works in detail.
ZeRO Offload
“ZeRO-Offload enables large model training by offloading data and compute to CPU. To preserve compute efficiency, it is designed to minimise the data movement to/from GPU, and reduce CPU compute time while maximizing memory savings on GPU”
Quote from original paper

Biggest trainable model; chart based on 32GB Tesla V100 Source: ZeRO-Offload: Democratizing Billion-Scale Model Training, Ren et al. (2021),
Effect on Memory: The below figure shows how parameters, gradients and optimiser states are distributed in the stages. It also shows how to calculate the memory consumption, where n is the number of devices, k is the multiplicator for the optimizer states (here: parameters = 1 unit, gradients = 1 unit, optimizer states = 6 units), and Ψ for the parameters of the model (in billion). Also, it shows the communication overhead that is caused by moving the data between devices, where it shows that stage 3 has some communication overhead.

Source: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, Rajbhandari et al. (2019)
Usage in DeepSpeed:

LoRA: Low-Rank Adaptation of Large Language Models
Paper: LoRA: Low-Rank Adaptation of Large Language Models, Hu et al. (2021)
Low-Rank Adaptation of Large Language Models (LoRA) to reduce the memory requirements by adding additional parameters to the model (specifically the attention layers) that are placed in parallel to the existing ones. What sounds counterintuitive at first glance (why should more parameters decrease memory consumption), is based on the idea that only those new parameters are trained while the existing ones are frozen. Because there are fewer new parameters the required memory for gradients and optimizer states are reduced.

Matrix Factorization, Source: https://predictivehacks.com/non-negative-matrix-factorization-for-dimensionality-reduction/
LoRA is based on the principle of matrix factorization, which involves decomposing a large matrix into two smaller matrices with low rank. LoRA adaptively computes a low-rank approximation of the weight matrix during training, which reduces the memory required to store the full weight matrix. LoRA has been shown to achieve significant memory savings without sacrificing accuracy, making it a valuable tool for deep learning practitioners dealing with memory constraints.
Effect on memory:

Source: lesswrong.com
All the existing parameters are frozen and only the newly added LoRA parameters trained. That reduces the number of trainable parameters (and therefore) gradients and optimizer states to a single digit percentage of previous parameters. This is so significant, the technique even lead to some concerns in Google whether the ability to train LLMs is still enough to maintain a competitive edge.
Usage in DeepSpeed
Not implemented in DeepSpeed directly, but only DeepSpeed chat.
Quantization
The majority of memory utilised by machine learning models consists of parameters such as weights and biases. They are saved as floating numbers, and for years, the standard has been using 32-bit floating numbers to provide higher precision and the ability to incorporate more information. Overall, it might be a good idea to decrease precision, but also decrease the memory usage.
The most common ways to use quantization is post-training quantization. You train the model and afterwards reduce the precision of your floats. The simplest way of doing that is just converting your float32 to float16. The little experiment from TensorFlow shows that this can be achieved without sacrificing too much performance.

Source: https://blog.tensorflow.org/2019/08/tensorflow-model-optimization-toolkit_5.html
In addition, there are also ways to quantize models into 8 or 4bit numbers. However these methods use some tricks to account for the precision loss. LLM.int8() for example considers outliers in a separate matrix multiplication. QLoRA (a combination of LoRA and quantization) uses 4 bit-float and shifts the distribution to be normally distributed.
Effect on memory
Theoretically you can quantize parameters and activations alike. However, I only came across parameter quantization so far. QLoRA for instance freezes all weights and only trains the few LoRA weights. So, memory requirement for gradients and optimizer states drop quite drastically. The main memory consumption is then caused by the parameters which are quantized.
Usage in DeepSpeed
There are quite lengthy descriptions about parameter quantization and activation quantization in the documentation.
Activation Checkpointing
Activation Checkpointing involves storing intermediate activation values in memory during the forward pass of a deep neural network. By selectively storing only some of the activations and recomputing the others during the backward pass, the memory requirements can be significantly reduced. This technique trades off computation time for memory consumption, ass recomputing some of the activations during the backward pass may require additional computations. Activation Checkpointing has been shown to be effective in training deep learning models with limited memory resources, allowing for the training of larger models that would not fit in the memory of a single GPU or machine.
Here is some visualisation of backpropagation w/wo activation checkpointing!
Traditional Backpropagation

Without memory

Checkpointing

Source: Fitting larger networks into memory (medium)
Effect on memory
Only uses O(sqrt(n)) memory for the activations. There is a paper from Korthikanti et al. that describes activations of transformers in detail.

Source: Reducing Activation Recomputation in Large Transformer Models, Korthikanti et. al, 2022
Usage in DeepSpeed:

Gradient Accumulation
Gradient accumulation is a technique used in deep learning to train large models with limited GPU memory. It involves accumulating the gradients from multiple mini-batches of training data before updating the model parameters. Instead of updating the parameters after each mini-batch, the gradients are summed up over a predefined number of mini-batches, and the parameter updates are applied at the end of the accumulation process. By accumulating gradients from multiple mini-batches, the memory consumption of activations can be reduced. This is because, during the forward pass, the intermediate activation values need to be stored in memory until they are used during the backward pass to compute the gradients. With gradient accumulation, the intermediate activation values are used to compute gradients for multiple mini-batches before the parameter updates are applied, reducing the amount of memory needed to store intermediate activation values.
Effect on memory
Reduces the gradients.
Usage in DeepSpeed:

Summary
Personally, I found it interesting to dive deeper into how memory consumption for neural networks work. I think, it is annoying to try out the latest tutorials, running into OOM errors and not knowing why.
Luckily, my employer Schibsted is very supportive of learning and I got the time to work on the article and memory calculator during one of our projects. The memory tracking library was a weekend project. Also, ChatGPT helped a bit in shaping some of the formulations.